Generating evidence for AI solutions: understanding ‘model evidence’ and ‘solution evidence’
Generating evidence for AI solutions: understanding ‘model evidence’ and ‘solution evidence’
For detailed insights on the evidence needed for AI solutions in healthcare, read the recent white paper published by Prova Health.
Trust and confidence are core factors influencing the adoption of artificial intelligence (AI) in healthcare. Vital to fostering this trust and confidence is robust evidence. This is true for all digital health solutions, and particularly AI-based solutions.
However, generating strong evidence for digital health solutions, including AI-based solutions, is a significant challenge for developers. This remains a hurdle to the wider adoption of potentially impactful products. As of 2022, 44% of digital health companies in the USA had no regulatory filings or published clinical trials for their products (Day et al., 2022).¹
Model evidence vs. solution evidence
AI-based digital health solutions require validation at two distinct levels. These relate to the algorithm (generating “model evidence”) and the product in which the algorithm is embedded (generating “solution evidence”). This reflects the fact that an AI model forms part of a digital solution, and once a model has been internally and externally validated from a data perspective, the solution as a whole must be evaluated.
Methodologies used to accomplish this are similar to those used to evaluate other types of digital health technology. Clinical pathways need to be scrutinised pre and post implementation to ensure that any improvements are delivered.
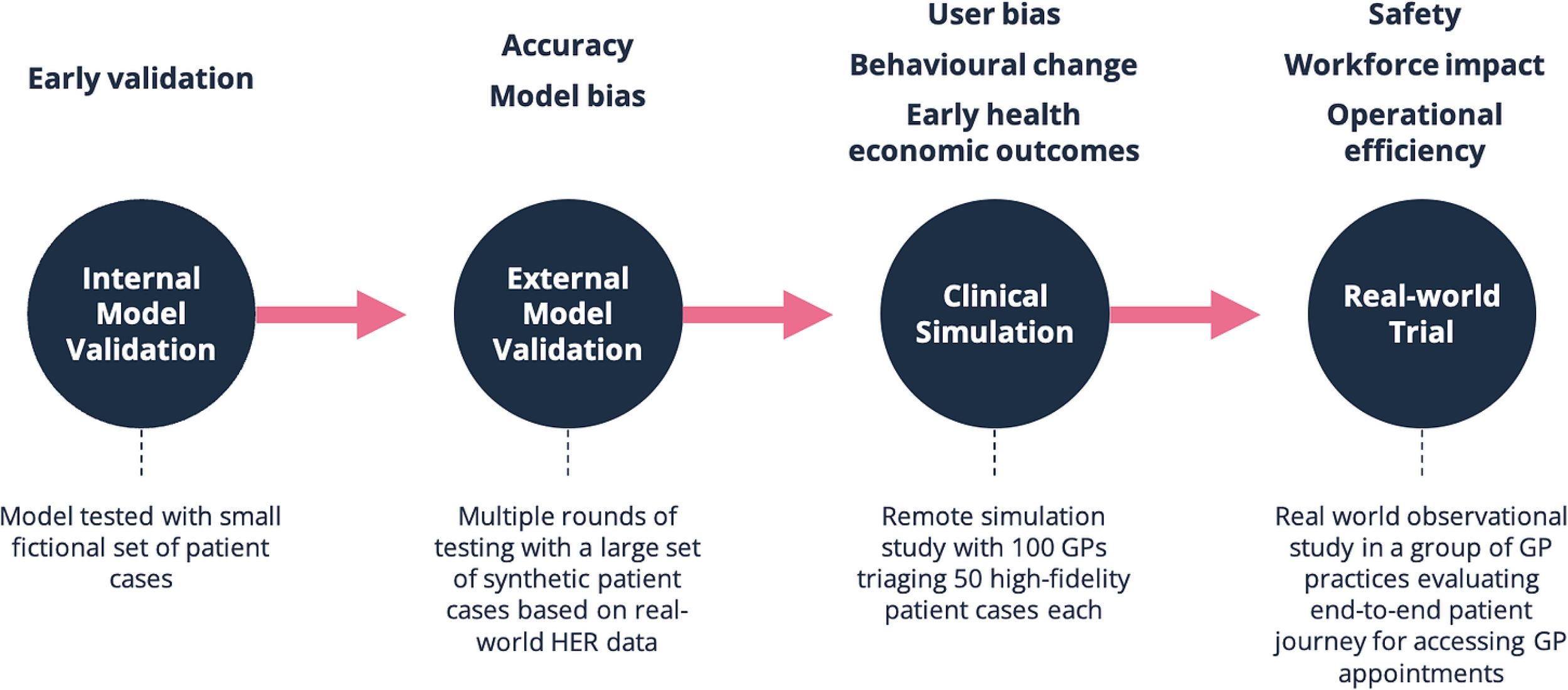
Figure 1. AI evidence roadmap for a hypothetical patient triage tool
In simple terms, developers of AI solutions (and those wishing to adopt them) should answer with robust evidence at least the following questions:
Is the solution addressing a real clinical or operational problem?
Does the model perform well on the developer’s own datasets?
Does the model perform well to external datasets?
Does the solution that includes the model address the problem effectively?
Does the solution reduce or eliminate existing biases and inequalities?
Does the solution deliver value for money to the client?
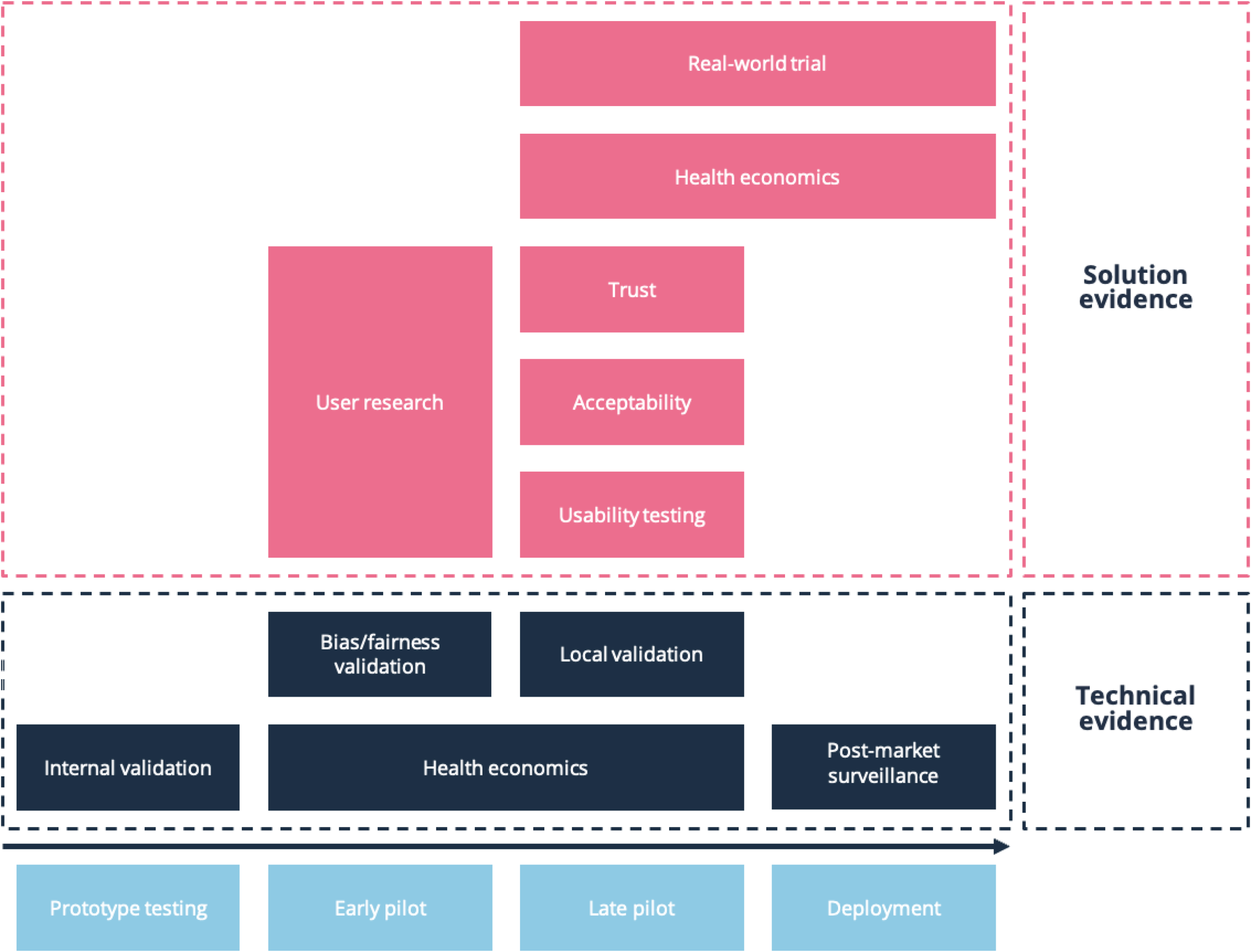
Figure 2. Factors contributing to technical and solution evidence
Model evidence consists of internal and external validation
Innovators develop AI models using specific data and conduct internal validation. This indicates how accurate and reliable a model is, but conclusions drawn are limited to the use of the model with the dataset that the developer has access to. Testing on external data (external validation) demonstrates how well the model performs on other datasets, assessing its ‘generalisability’.
It is important to note that valuable evidence can be generated early in a model’s development that is not limited to purely model validation. Utilising methods like clinical simulation at this early stage can facilitate the assessment of factors that impact trust and confidence in a model. For example, evaluating how the presentation of auxiliary data in addition to AI-generated outputs impacts the user’s clinical decision making. This can be done in parallel with the purely technical model validation.
Various frameworks have been developed to help standardise expectations and reporting outcomes for specific types of AI technologies. These are helpful for developers building a product that matches one of these use cases (see Table 1).

Table 1. AI evaluation and clinical trial reporting guidelines and tools²
Challenges in evaluating AI-based solutions
From an understanding and explainability perspective, one technical challenge is that AI models can be considered a “black box” due to difficulty in understanding how the model is producing an output.³ Other significant challenges are a lack of sufficient data to train AI models on, and ensuring data is from a population representative of that in which the solution will be deployed.¹ These may be difficult to address due to the large datasets required to train AI models. In some clinical specialties, such as ophthalmology, there exists a large library of anonymised imaging data for training AI models. However, this is not the case in many other clinical areas, making it more difficult to optimise and train algorithms.
Data privacy and security are critical in the adoption of AI tools.⁴ AI systems rely heavily on large datasets. Ensuring that patient information remains secure and confidential is paramount. Breaches in data privacy and security can erode patient trust and have significant legal implications. The move towards secure data environments in the NHS in England is one example of how data can be better safeguarded.⁴ Key challenges for the translation of AI systems in healthcare include those intrinsic to the science of machine learning, logistical challenges in implementation, and consideration of barriers to adoption as well as of any necessary sociocultural or pathway changes.
Biases and inequities should be minimised
The data on which AI models are trained should be representative of the populations in which the models will be deployed. Data should also have sufficient breadth and depth to capture the multitude of clinically important associations between ethnicity, demographic, social and clinical features that may exist.³ Developers should build in sensitivity checks to reduce bias. This can include using simulated datasets and running counterfactual simulations during design and later stages of development.³
As an example, the following should be documented by developers when considering potential biases and inequities in AI algorithms⁵:
A description of the dataset and its representativeness of different minority ethnic populations.
What measures were taken to prevent and address bias across different minority groups in:
the data used
defined outcom
modelling
Whether the performance of the algorithm has been tested and validated on different minority ethnic subgroups.
Ethical considerations regarding how the algorithm will be used and whether there are any risks of creating or perpetuating ethnic disparities in health.
Evidence across the product life cycle
In the context of digital health solutions, “evidence generation” is a broad term for the process by which various types of evidence are produced to support product development and validation.⁶ Many types of evidence can be generated at any stage; however, certain types of evidence are more strongly associated with specific stages. For example, product development is informed from the earliest stages by techniques such as secondary research (reviewing existing research, which helps innovators to better understand a clinical problem), user research (which can help validate a solution concept), and A/B testing (which allows comparison of different versions or features). Later, when developers have a well-defined product, clinical data demonstrating safety and clinical performance may be critical for regulatory certification, and economic analyses will be important for demonstrating value to health systems in order to sell a solution.

Figure 3. Examples of evidence generation at different stages of the product life cycle
For more insights on the evidence needed for AI solutions in healthcare, read the recent white paper published by Prova Health.
Prova Health supports digital health innovators with evidence generation.
To discuss generating evidence for your digital solutions, email hello@provahealth.com
Dr Des Conroy is a Digital Health Consultant at Prova Health. As a medical doctor he has worked in clinical practice in the UK and Ireland. He has experience developing and clinically validating artificial intelligence-based Software as a Medical Device (SaMD) products, and supporting their deployment at a global scale. At Prova Health, he has led research into evolving evidence standards and reimbursement models in digital health.
Dr Mehul Patel is a GP and Health Informatician. He has worked in Clinical Lead and Clinical Safety roles for multiple digital health companies. He holds an MSc in Health Informatics from UCL/University of Manchester. He has completed a Health Education England Fellowship in Informatics involving national-level informatics projects within the NHS.
Dr Saira Ghafur is Co-founder and Chief Medical Officer of Prova Health. She is an honorary consultant Respiratory Physician at St Mary’s Hospital, London, and a digital health expert who has published on topics such as cybersecurity, digital health adoption and reimbursement, data privacy and commercialising health data. She is Co-founder of mental health start-up Psyma and holds a MSc in Health Policy from Imperial. She was a Harkness Fellow in Health Policy and Practice in New York (2017).
References
Day S, Shah V, Kaganoff S, Powelson S, Mathews SC. Assessing the Clinical Robustness of Digital Health Startups: Cross-sectional Observational Analysis. J Med Internet Res. 2022 Jun 20;24(6):e37677. doi: 10.2196/37677.
O’Brien N et al. Addressing racial and ethnic inequities in data-driven health technologies, 2022. https://spiral.imperial.ac.uk/handle/10044/1/94902
Ghafur S et al. NHS Data - Maximising its impact for all, 2022. https://spiral.imperial.ac.uk/handle/10044/1/103404
Review into bias in algorithmic decision making. Centre for Data Ethics and Innovation, 2020. https://assets.publishing.service.gov.uk/media/60142096d3bf7f70ba377b20/Review_into_bias_in_algorithmic_decision-making.pdf
Digital health solutions and evidence generation. (2023, March 15). https://healthcaretransformers.com/digital-health/current-trends/digital-health-solutions-evidence-generation/